In the world of quantitative trading, D.AT simplifies the process of machine learning model development
by providing standard data engineering and significance testing. D.AT provides an integrated
solution for segmenting time-series data to isolate significant trends, cleaning datasets to enhance reliability,
aggregating varied data streams for a comprehensive view, engineering features to pinpoint key influencers, crafting
strategy-oriented labels, and strategically splitting data to avoid common biases. Equipped with functionalities
that streamline these critical stages, D.AT empowers you to create robust and accurate predictive models,
positioning you a step ahead in the stock market game.
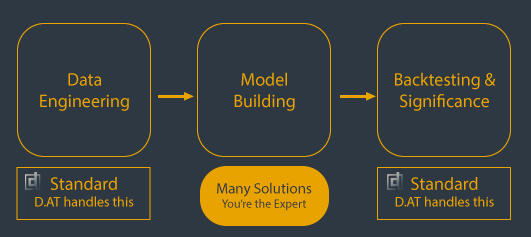
Building a stock prediction model with D.AT involves three key stages: Data Engineering, Modeling, and
Backtesting/Significance. Data Engineering refines raw stock data into tailored datasets. This groundwork is
streamlined by D.AT, allowing users to focus on the exciting Modeling phase, where expertise shines as they
craft prediction models. Lastly, in the Backtesting/Significance phase, models are tested against random
simulations to measure their true predictive power. While users bring their expertise in model creation, D.AT
simplifies the essential yet tedious tasks of data preparation and backtesting.
Stock Data Engineering
Cleaning:
Data cleaning is the process of identifying and correcting inaccuracies in datasets, ensuring
consistency and reliability in your analyses. This fundamental step in data preparation not only removes
noise but also enhances the quality of your machine learning models, paving the way for more accurate
and insightful stock predictions.
Windowing:
The process of segmenting time-series data into regular sized smaller chunks is a common first step to
most ML methods.
In the case of the majority of neural network techniques, fixed input layer size is a requirement.
D.AT provides a homogenous method for streamlining the process.
Aggregation:
Data aggregation involves merging various data streams, such as different stock time series and diverse
measurement types including price, sentiment, and macro-economic factors, into a cohesive dataset. This
process facilitates comprehensive analysis, allowing users to develop more informed and nuanced machine
learning models for precise stock price predictions, leveraging insights garnered from multiple data
facets.
Feature Engineering:
Feature engineering is the technique of selecting and transforming variables when creating a predictive
model. It is a critical step in machine learning that enhances model performance by extracting and
constructing meaningful inputs from raw data, helping to pinpoint key influencers in stock price
predictions with higher precision and reliability.
Labeling:
Labeling within D.AT allows users to define specific trading strategies as actionable indicators or
"labels" in the dataset. For instance, you can create a label that triggers a "buy" signal at market
open, with an exit parameter set at a 5% gain within the next 10 trading days or a 3% stop-loss. This
functionality facilitates the creation of practical, strategy-oriented machine learning models that can
simulate and potentially capitalize on identified market opportunities.
Splitting:
Train/test data set splitting in D.AT is designed to mitigate common pitfalls like look-ahead bias and
survivorship bias, ensuring a more realistic and reliable model evaluation. By strategically dividing
data into training and test sets, it fosters the development of machine learning models that are both
robust and capable of making accurate predictions, paving the way for trustworthy stock price forecasts.